Is it time to replace REST with RPC?
Support this website by purchasing prints of my photographs! Check them out here.In the eyes of the Consumer a RESTful Provider offers a lucrative promise. Communication happens over the well-understood HTTP protocol. Conceptually these services are quite easy to understand. The author of a RESTful Provider takes the complex operations and data beneath the API's surface and abstracts it in such a way as to be represented by the four CRUD operations spread over various endpoints.
CRUD stands for Create, Read, Update, and Delete, and are typical operations applied to data in many a system. Create correlates to an HTTP POST, Read to GET, Update to Put/Patch, and Delete to DELETE. These are the verbs of our application and Endpoints are our nouns.
As an example of this we can Create an Employee with POST /employees, Fire an Employee with DELETE /employer/acme/employees/wile-e-coyote, or Update the Employee with PUT /employees/roadrunner. Shallow endpoints, like /employee, can be used to represent a collection of entities, the slightly deeper /employee/{employeeId}, can represent a single entity, while even deeper endpoints, such as /employer/{employerId}/employee, can be used to represent parent/child relationships.
REST is a bit of an overloaded word. It's so overloaded that as an industry we've invented the word RESTful to mean REST-like. There is no exact way to implement a RESTful service; certainly you can interact with a few of your favorite HTTP API's which promise REST and they'll all behave differently. Some of these differences occur on the fringes of the HTTP protocol itself. What sort of headers do we provide? What query parameters do we use? If we refer to multiple things using a query parameter which encoding format do we use:
?a[0]=foo&a[1]=bar
?a[]=foo&a[]=bar
?a=foo&a=bar
Other differences between implementations occur in the data modeling itself. What is the best way to translate our data into endpoints? How do we rename or move an entity? What kind of meta data should the response body contain?
Perhaps the most troubling class of questions we have to ask ourselves can be exemplified as follows: How do we RESTfully represent sending an email to a user? The action/verb we really want to represent is "email". The noun/target of this action is a particular user. Sending an email is an ephemeral action we want to perform, whereas REST prefers to work with collections of more permanent data. One RESTful solution to this problem would be to have a /emails collection (with email being our noun instead of verb). We could then POST to this collection to send an email (we're creating an email after all). The request body could then contain information about the email as well as the User ID. This could create a permanent email resource that we could later refer to.
This approach requires a bit of abstraction on behalf of the engineer working on the Producer. Instead of firing and forgetting an email perhaps we're now modeling it as an email resource and storing it in a database. If, somewhere within the Provider sourcecode, we have a function send_email(user_id, text), we ultimately need to create a controller which receives the request, parses data from URL and headers, parses JSON data from the body, and maps the controller to our underlying function. All this abstraction and effort to represent our simple function RESTfully can start to add up as we implement more and more endpoints in our Provider.
REST is an alternative to RPC. RPC stands for Remote Procedure Call and at its heart is a way to remotely execute a function by name while passing in arguments. What this means is a Consumer can "directly" call out to the aforementioned send_email(user_id, text) method in the Producer without needing to go through the REST abstractions. This doesn't mean you should expose every possible function in your server without abstraction, far from it in fact, but it does allow us to conceptually "just send an email" much easier.
From a more technical perspective HTTP has a "shortcoming" of its own; HTTP messages contain a bit of overhead in the form of headers. Typically every message involves reestablishing a TCP connection between the Consumer and the Provider. HTTP is a high level protocol which sits above TCP. This connection takes a non-trivial amount of time to establish, especially when in an environment where many messages are being sent in a short amount of time.
Let's look at a few benchmarks with different protocols and serialization methods. In these examples the objects will be of the same structure and their sizes will fluctuate by a few bytes. We'll compare the request and response sizes of the TCP data. The TCP header is about 66 bytes in these situations.
Benchmark 1: JSON over HTTP
JSON over HTTP, probably being the most common form of inter-service communication, will serve as our baseline. As mentioned above it can be a little on the chatty side.
The size of our requests are around 221 bytes, which includes the Request line, the request headers, and the request body. The response weighs in at 141 bytes and also includes HTTP meta data.
With each of these different approaches we will need to serialize and deserialize the payload itself. However, with HTTP, we also need to parse and generate the request and response headers which adds some overhead.
While observing network traffic using Wireshark we can see many different packets getting sent for every HTTP request/response being sent. Unfortunately, and this may be a misconfiguration of my machine, DNS lookups are frequently made.
In this screenshot, and each of the following screenshots, red represents the request message and the blue is the response message, both are shown in ASCII.
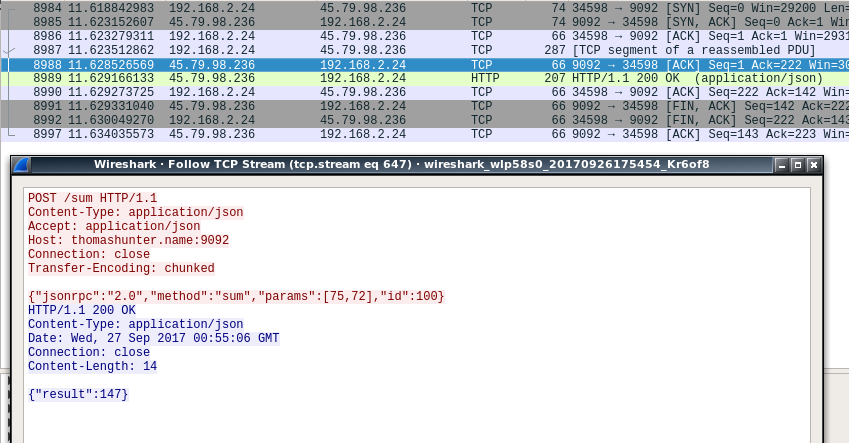
Wireshark Capture of HTTP/JSON TrafficA lot of this information our service just doesn't care about. For example, a service which only accepts JSON and only replies with JSON doesn't need the Content-Type or Accept headers. Status codes can become redundant with an error message located in the body. The Host is usually ignored by applications (though it is useful for incoming requests when a web server represents multiple domains). Knowing the date of the server isn't too important, either. Overall this example is a simple and contrived one as most HTTP requests and responses contain many more headers.
Benchmark 2: JSON over TCP
In this benchmark we maintain a single connection between the Consumer and the Producer. We're able to send messages much more efficiently. We no longer need the headers which describe the content we're giving and the content we're expecting.
TCP is much more efficient, with the request totaling 60 bytes and the response totaling 40 bytes.
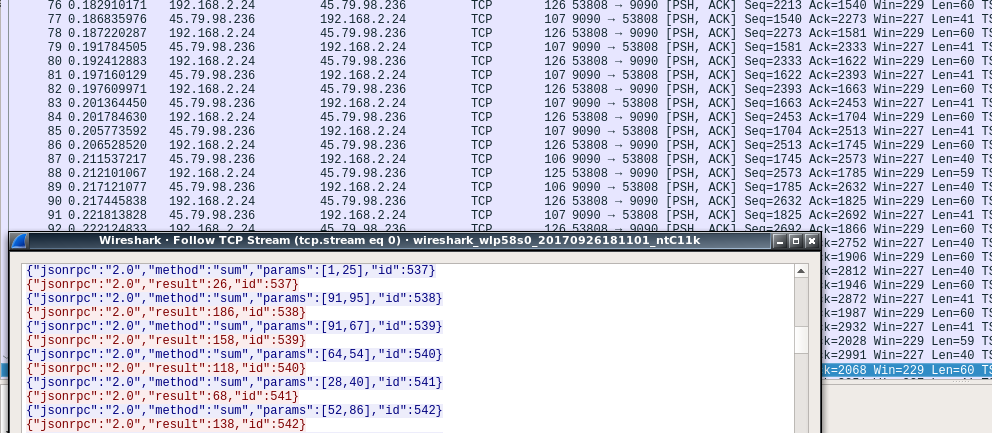
Wireshark Capture of TCP/JSON TrafficAs you can see in the screenshot we go from having several messages being sent to having a single request and response message being sent.
Benchmark 3: MessagePack over TCP
In this benchmark we can take our payloads and shrink them a bit by using MessagePack. MesssagePack is a binary format for representing JSON and results in a smaller payload size. Converting from JSON to MessagePack is straightforward and doesn't require a schema, though alternative binary representations usually do.
When we represent our requests and responses using MessagePack this results in requests of about 40 bytes and responses of about 27 bytes.
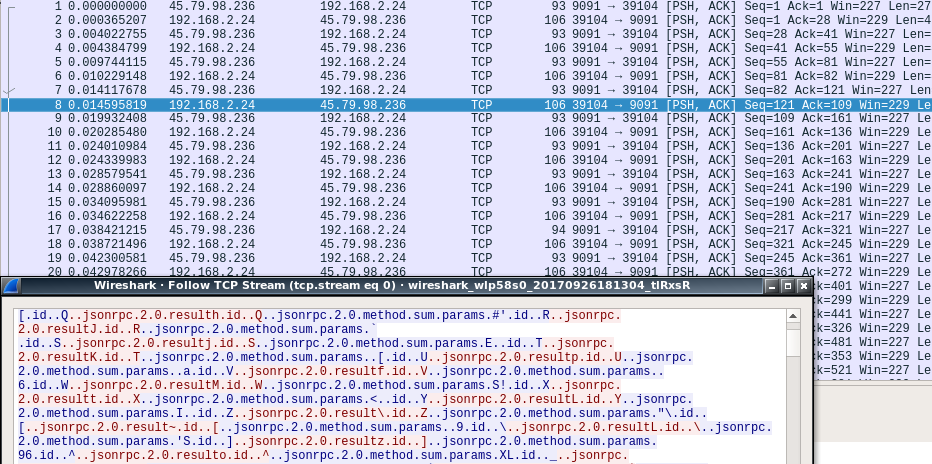
Benchmark Results (Using Node.js)
If you would like to run these benchmarks yourself or see how they were written, take a look at tlhunter/node-rpc-playground. The results I was able to attain are posted below. My hypothesis before running these was that TCP would always be faster than HTTP, and that when higher latency is involved MessagePack will be faster than using JSON.
| Scenario | Localhost | SF -> Fremont | SF -> London |
|---|---|---|---|
| Node | v8.5.0 | v8.5.0 | v8.5.0 |
| Ping | 0.065 ms | 4.364 ms | 142.5 ms |
| HTTP + JSON | 3268 o/s | 65.40 o/s | 3.479 o/s |
| TCP + JSON | 15886 o/s (4.9x) | 239.6 o/s (3.7x) | 6.963 o/s (2.0x) |
| TCP + MP | 8004 o/s (2.4x) | 203.9 o/s (3.1x) | 6.902 o/s (2.0x) |
Take these results with a grain of salt! As you can see TCP is anywhere between 2x faster, when traveling long distances, and 5x faster, when distance isn't an issue. If communication happens in the same datacenter, e.g. between your microservices, expect to see a 4x improvement over HTTP.
It's a little unfortunate that MessagePack is always slower than JSON. If you were to run these benchmarks using a language other than JavaScript you would probably find that the MessagePack results are faster than using JSON. JavaScript lives and breathes JSON and the built-in function JSON.stringify() has had plenty of time to be optimized. There are also different binary representations which should be faster and yield smaller payloads such as Thrift or Protocol Buffers.
More about JSON RPC
The JSON payload we've been using in the benchmarks adheres to a specification called JSON RPC. The JSON RPC specification is dead simple! I suggest you give it a quick read. The specification defines a very simple envelope for naming and calling functions and getting the results.
One important part of the JSON RPC standard is that we need to uniquely track requests and responses and have a way to correlate them. To do this we use an ever-incrementing integer ID. Since JSON RPC is designed to run outside of the request/response paradigm of HTTP, using a single connection, without guarantees of message ordering, correlating these messages needs to be done via an identifier in the body. In the benchmarking scripts I've done this by hand by creating a pool of ID's and their callbacks, but we could have used a library which would abstract this from us.
It's worth mentioning that things which are a standard in HTTP will need to be reimplemented using JSON RPC. Consider the following request where we use the Accept-Language header to make a request for a list of resources (other important data has been highlighted as well):
GET /employees?perpage=10&offset=30 HTTP/1.1
Host: api.example.org
Accept: application/json
Content-Type: application/json
Accept-Language: en-US, en, *
To represent that same request using JSON RPC we would need to invent our own standard. JSON RPC allows two methods for passing in arguments, the first being an array (aka ordered parameters) and the second is with an object (aka named parameters). If we choose the latter method we could use a parameter named language:
{
"method": "list_employees",
"params": {
"language": "en-US",
"perpage": 10,
"offset": 30
},
"id": 1,
"jsonrpc": "2.0"
}
Note that this JSON RPC request is approaching the size of our HTTP request.
With HTTP being such a well known standard we get some nice bonus features. As an example, HTTP clients instinctively know which types of requests can be retried in the event of a failure. A GET request is idempotent, meaning there should be no side effects if repeated, and can be retried. A POST request is not idempotent; if a failure occurs we don't know the state of the server, retrying could create multiple entries. With an RPC style service we lose this innate understanding about the nature of a request. Retry logic needs to exist at the application level instead of the library level.
Takeaways
If you currently produce or consume services within an organization and have to deal with high volumes of messages via HTTP/REST, consider adopting TCP / RPC. If you find latency or network saturation to be any sort of bottleneck then this advice applies even more so. Before making any jump run your own benchmarks in your own datacenter using whatever language you build services in.
Switching to RPC doesn't have to be all or nothing. You'll find that some internal services can't migrate away from HTTP. You'll also find that most of the world expects to consume a public API via JSON over HTTP. Taking a hybrid approach is a valid solution.
PS: Some of the content in this article is based on a book I recently published, Advanced Microservices. If you found this article insightful please check it out!
Thomas has contributed to dozens of enterprise Node.js services and has worked for a company dedicated to securing Node.js. He has spoken at several conferences on Node.js and JavaScript and is an O'Reilly published author.