mig: The Universal Database Migration Runner
Support this website by purchasing prints of my photographs! Check them out here.I've always wanted a universal database migration runner that I would use with any project backed with a SQL database. mig was built to fulfil this need.
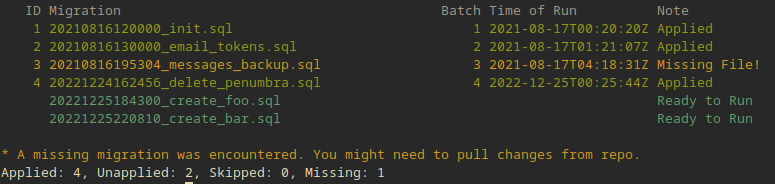
mig migration list
What is a Database Migration?
Nearly every interaction that we make to a SQL based database is by executing SQL queries. This includes the data manipulation operations that our applications trigger, such as INSERT, UPDATE, SELECT, and DELETE queries (often called Data Manipulation Language or DML). But, it also includes operations that modify the database tables themselves, such as UPDATE TABLE (often called Data Definition Language or DDL). Traditionally, one might execute such table modification operations by hand, forever relying on the current state of the database as the source of truth. You'd be surprised by how many companies have "a single database" and can achieve this.
A few things have made it impractical to simply run one-off DML queries and be done with it. With the rise of version control systems and the proliferation of "everything as code" it has become a necessity to keep track of these modifications in a repeatable and auditable way. When it comes to hosting databases in multiple environments (think staging vs production or USA vs UK) it's important that the DML queries that our applications run in one location also function in another. And when it comes to distributed teams, developers need to know that their local database copy has an up-to-date schema.
A migration can therefore be thought of as a query that modifies the shape of a database in some manner. Such migration queries are saved to disk to be checked-in to version control. These changes can then be audited by other engineers (such as by a pull request). It even allows migrations to be checked in alongside code changes! Over time a trail of migrations is available, each with a timestamp and an author, and other engineers can check version control history to know the exact context for any given database change.
A migration runner is a program that runs migrations. It's important to know which migrations have already been applied and so additional state is stored, usually in the database itself, about the progress of migration executions. It's also important to wrap changes in transactions, to offer the ability to revert changes, ensure migrations are executed in exact order, etc. This is why we execute them programmatically instead of by hand.
There are many migration runners out there and they're usually associated with a given platform. Take Node.js for instance, where the most popular migration runner is Knex.js. My fourth book, Distributed Systems with Node.js, covers Knex.js migrations in detail. Python has Alembic (among others), Ruby on Rails has a migration runner. If you can name a language or platform that touches a database it probably has at least one migration runner.
So, that migration runner problem is pretty much solved, isn't it?
What's Wrong with the Existing Migration Runners?
While one cannot deny the convenience of using a platform-specific migration runner they do come with philosophical problems. If, say, the best migration runner ever created is one for Node.js, and there are many amazing articles devoted to usage and edge-cases and brilliant multi-stage migration patterns, that migration runner will never be able to reach critical mass. Despite being best of class there will forever remain projects that can't adopt it. Python project maintainers, for example, aren't going to want to add an additional dependency on Node.js just to run migrations.
Another problem comes with the melding of platform-specific patterns into migration runners. At the end of the day migrations contain what should be very static SQL code. However, many migration runners allow or otherwise require developers to write queries using whatever abstractions a library provides. This results in a form of vendor lock-in where migrations can't be simply migrated to other tools. It also makes things a headache for any Database Administrators (DBAs) that need to audit these schema mutations.
As an example, here's a Knex.js migration file:
exports.up = function(knex) {
return knex.schema
.createTable('users', function (table) {
table.increments('id');
table.string('first_name', 255).notNullable();
table.string('last_name', 255).notNullable();
});
};
exports.down = function(knex) {
return knex.schema.dropTable("users");
};
exports.config = { transaction: false };
Say that you know what SQL looks like, but you're not all that familiar with JavaScript. Would you be able to figure out that migration? Probably. But it would certainly be difficult to write a migration from scratch. To do so you would need to either learn the API or at least maintain a tab for it. If you happen to be a DBA or platform engineer working on coordinating a security fix across a polyglot company, this is going to mean a lot of reference checking and a lot of edge cases to worry about.
I firmly believe that database migrations should be expressed entirely in pure SQL. Ironically, in my article Why you should avoid ORMs, while I sing praises for Knex's Query Builder pattern for application code (DML queries), I do feel that migrations should be facilitated entirely in raw SQL.
To Knex's credit it does allow expressing migrations as SQL. Many platform-specific migration runners support this as well. Here's an example from a project of mine that uses Knex.js:
export const up = async (knex) => {
await knex.raw(`
ALTER TABLE channels ADD COLUMN virtual BOOLEAN NOT NULL DEFAULT false;
`);
};
export const down = async (knex) => {
await knex.raw(`
ALTER TABLE channels DROP COLUMN virtual;
`);
};
While it's true that this is closer to our pure SQL approach, it's still notably not pure SQL. This is a JavaScript file, one that depends on a certain version of the JavaScript language (arrow functions, async keyword) and therefore a certain version of Node.js. Do you know which versions of Node.js can execute this file? Sure, we could look it up, but that just "one more thing". Another drawback is the lack of syntax highlighting in most editors. Sure, Webstorm will probably figure it out, and I bet VS Code has a plugin for that, but most editors (and even my blog syntax highlighter) won't figure it out.
And finally, we have declarative SQL code wrapped in imperative JavaScript. If you want to extract the queries from a bunch of these migration files, you're going to need some sort of JavaScript runtime. Again, this is all forms of vendor lock-in.
What does mig have to offer?
There's a recent trend of replacing interpreted tooling used in interpreted projects with compiled tooling (think esbuild). One reason for this is that in emergency scenarios we don't want to run a bunch of npm or pip or gem commands. We don't want to have to install language runtimes or interpreters and deal with their dependencies and version compatibility issues. It can also be a bit excessive to spin up a Docker container depending on the scenario. And when it comes to Continuous Integration (CI), it's not necessarily true that the environments that are configured to run your application are the same environments that will run your migrations and other build tooling.
mig is available as precompiled binaries targeting specific operating system. For example, to run it in a Docker container, you would run the following steps:
wget https://github.com/tlhunter/mig/releases/download/v0.2.0/mig-v0.2.0-linux-amd64.tar.gz
tar -xf mig*.tar.gz
mv mig /usr/bin
The migration files used by mig are written in pure SQL. These migrations are very portable and can be translated into queries used by other migration runners if a developer wanted to jump ship. Here's an example of a migration file:
--BEGIN MIGRATION UP--
CREATE TABLE users (
id serial NOT NULL PRIMARY KEY,
username varchar(24) UNIQUE
);
--END MIGRATION UP--
--BEGIN MIGRATION DOWN--
DROP TABLE users;
--END MIGRATION DOWN--
And look at that, perfect syntax highlighting! To developers who know SQL there are zero surprises with the code here. At the end of the day it's just pure SQL. In a disaster scenario one could just copy and paste the code into a SQL console.
Internally, mig is written in Go, and that makes it a breeze to compile the program for different platforms. The resulting binaries are statically compiled, which is a fancy way of saying you shouldn't have to deal with compatibility issues with system libraries like OpenSSL or libc. Another way of putting it is you can run mig in an empty Docker container with zero dependencies installed.
So that's mig. If you'd like to check in on the progress it's available on GitHub at tlhunter/mig. As of this writing it supports MySQL and PostgreSQL with plans to support other dialects like SQLite. I plan on writing additional guides, like how to go about creating complex multi-stage migrations with zero downtime.
Thomas has contributed to dozens of enterprise Node.js services and has worked for a company dedicated to securing Node.js. He has spoken at several conferences on Node.js and JavaScript and is an O'Reilly published author.