On Migrating from Wordpress to Static Markdown
Support this website by purchasing prints of my photographs! Check them out here.The website you're currently reading has evolved much over the years. Its humble beginning circa 2006 was that of a web programming tutorial site, nucleocide.net: a hand-rolled PHP/MySQL website infested with SQL Injections. Years later it migrated into a business, renownedmedia.com: a Wordpress blog for an LLC of mine. Finally, inspired by David Walsh, the site became thomashunter.name: another Wordpress blog with a dozen plugins, an ever-changing layout, and an attempt at personal branding.
Fast forward to 2018 and the site has amassed over 400 posts. Content was copied and pasted from platform to platform along the way. Images were haphazardly uploaded, screenshots retaining their default messy macOS filenames. What could have been an empire of original content was reduced to a mire of digital hoarding that only served to distract the poor reader from morsels of useful content.
Over the past week I finally cleaned out this messy closet of a website. Like the title gives away, the content has been migrated from the feature-rich Wordpress to a simple Markdown-based static site generator. What follows is an explanation of these changes and the benefits—and drawbacks—which come with them.
Philosophy
The current incantation of this site was made by following these simple guidelines:
Portability
CMSs and Blogging platforms come and go. Some store content as HTML, some as a proprietary format like BBCode, some as some sort of weird HTML hybrid thing (like Wordpress). Content can be stored in SQL, NoSQL, or even text files. I really wanted a simple format that I could easily migrate to the next big platform in several years. I chose the ubiquitous Markdown format and a simple directory of images.
Easy to Backup
Backing up the content of a website is imperative. When running everything in Wordpress the natural flow is to make changes in production, on a single server, performing the occasional manual backup. If the server dies then the content is forever lost. With this static site all the Markdown and images exist locally, rendered HTML and images are on a web server, and Markdown is committed to Git. If any single one of those sources were to fail the site could be reconstructed by consulting the other two sources.
Freedom
One thing I really wanted to avoid is vendor lock-in. Many people in our industry blog with Medium these days. I admit that I like to put copies of posts there occasionally, or even use it when blogging for an organization. However, whenever I have a post of mine hosted solely on Medium it just doesn't feel like I own it anymore. Also, if a post is hosted at medium.com—a site owned by a company—then it's not doing anything to increase the page rankings for thomashunter.name—a site owned by myself.
GitHub Pages were also appealing, though despite my love of their product it is still a form of vendor lock-in. I also didn't want to migrate content to a subdomain (for GitHub DNS purposes), and I want to easily host web applications next to content. Ultimately, serving HTML content via nginx, hosted on a VPS I control, provides all the flexibility I desire. SSH-ing in to occasionally run sudo apt update && sudo apt upgrade isn't that much of a maintenance overhead.
Noteworthy Features
There are many common anti-patterns employed by technical blogs; such issues are usually the fault of the underlying blogging platform, not the author themselves. While rebuilding this site I wanted to avoid these anti-patterns while also implementing practical new patterns.
Relevant Next/Previous Links
How many times have you clicked the Next link at the end of a Wordpress post, only to be taken to an unrelated post? Those links typically take the reader to the next or previous chronological post—a lesson about CSS followed by a story about a pleasing ham sandwich. This site only displays Next/Previous links when articles are part of a series. An example of this is Advice for Technical Public Speaking: Part 2 wherein the Next and Previous links will take you to parts 1 and 3.
Printable Content
Visit a Medium article and launch your browser's Print Preview feature and you'll end up with a few inches of margin and a trailing, empty page. This experience, while frustrating, is better than that of most websites. Now try the same thing on this site. The sidebar disappears and the footer gains small details to compensate. This is handled by the print-only CSS media query and looks something like this:
.print-only { display: none; } /* Hidden unless printed */
@media print {
aside { display: none; } /* Don't print the Sidebar */
main { width: initial; margin: 0; } /* Remove excessive margins */
.print-only { display: initial; }
}
Comment Consolidation
It is difficult track the myriad of conversations relating to a particular post. Consider when one is submitted to Hacker News, Reddit, and Facebook. How is a reader to ever join in the conversation? This site makes third-party comments a first-class citizen. For an example see Node.js and Lambda Three Part Series; at the end of the post are links to relevant Hacker News, Reddit, and Medium discussions.
Shadow (Canonical) Posts
One goal I've always had is that of a central location linking to every post I've written over the years; including guest blog posts published to other websites. However, a lot of those sites eventually suffer from bit rot, such as Hosting and Developing Cobalt Calibur on the MongoDB website. This site reproduces much of that content locally, such as this local version of that same post. Normally this would negatively affect search engine traffic, but with the help of the canonical meta tag, local "shadow posts" won't be listed in search engines.
<link rel="canonical" href="https://www.example.com/post-by-tlhunter" />
Valid Copyrights
Most sites use a generic site-wide template for the footer. Such a footer usually contains text like Copyright $YearSiteWasMade $EntityName or Copyright $YearSiteWasMade - $YearPageWasViewed $EntityName. Unfortunately, this means a website established in 2014, and that contains a blog post written in 2016, will incorrectly display a copyright of 2014. This site takes the timestamp of the rendered post and uses that for the footer date, ensuring the footer copyright is always accurate.
Deprecated Posts
Some posts are so old that their content is no longer accurate. However, they may still get a decent amount of views or be useful from a historical point of view. In these situations the post gains a frontmatter deprecated: true tag. This results in a large DEPRECATED banner being placed at the top of the page. Take a look at Database Administration using phpMyAdmin (2009) for an example of a decrepit post I just couldn't kill.
Search Engine Optimization
Compared to most modern webpages mine is pretty small. A cold cache will require about 400kb of uncompressed requests to load. Subsequent loads should only be ~10kb (depending on the amount of page content). The number of resources the site requires is fairly small: 1 advertisement, analytics, 1 JavaScript file for syntax highlighting, 1 CSS file, an avatar image, and web fonts. Perhaps more important for SEO is the rather simple DOM.
The URL structure changed during the migration, not for technical reasons but for the betterment of readers. Links to the site forever exist in forum posts and emails and pages all across the internet. We've all felt that enduring pain when trying to debug a technical problem, searching for hours, clicking a link in a forum post which promises to have the answer, only to have our hearts broken by a 404. To prevent this from happening I've given nginx a mapping of old URLs to new URLs and it will redirect requests accordingly:
rewrite ^/blog/support-me-on-patreon/?$ /posts/2018-02-12-support-me-on-patreon permanent;
rewrite ^/blog/advanced-microservices/?$ /posts/2017-06-19-advanced-microservices permanent;
rewrite ^/talks/$ /talks permanent;
This site is served via HTTPS which also boosts search rankings slightly. Adding HTTP2 support is still on the TODO list.
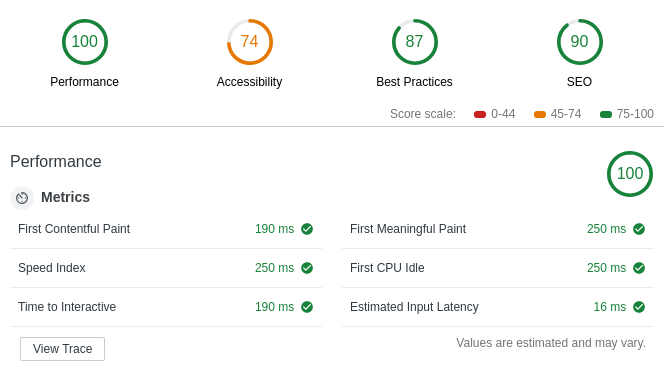
Google Chrome has a feature called Lighthouse built into its Web Inspector. This is helpful for fixing webpage performance. For example it will recommend things like consolidating network requests, adjusting cache expiration, finding images with missing alt attributes, etc. A few hours with Lighthouse helped make this site more efficient. Here's a screenshot of this site's current score:
Implementation
The static site generator is written in ~200 lines of synchronous Node.js code. For my workflow I copy a Markdown template file, alter a few lines of YAML frontmatter, and begin writing Markdown content. I can preview the website locally with npm run preview, build the changes with npm run build (all couple hundred posts recompile within 1 second), and deploy the changes using npm run deploy.
The site build script employs the following modules:
- js-yaml: Parse configuration YAML into Objects
- ejs: Render EJS templates into HTML
- gray-matter: Extract YAML from Markdown
- showdown: Render Markdown into HTML
- dateformat: Format
Dateobjects for Humans - html-word-count: Count words in HTML
- rss: Generate RSS feed
The frontend makes use of highlight.js for performing syntax highlighting—doing this server-side is on the TODO list.
If there weren't already dozens of competing static site generators out there I would open source this one.
Another convenient feature is that if the Markdown document contains a URL to YouTube, Vimeo, or a GitHub Gist, the URL is replaced with the appropriate HTML to embed that resource within the page. This Gist contains the code for performing such a replacement:
Deployment
Deployment is done by running npm run deploy which triggers a few lines of scp. I could have done something fancy with pushing commits to the web server and triggering a build but the benefit probably wouldn't be worth the setup time.
A side-effect of this new system is reduced overhead of hosting the website. With the server no longer running Wordpress or MySQL I was able to halve the Linode VPS hosting costs!
Drawbacks
I can no longer update the site using any device with internet access; instead it must be done on a development laptop. During the many years that I've been running websites this hasn't actually been necessary, but I can see it being a blocker for other writers.
Wordpress makes image insertion very easy. It'll create a YYYY/MM folder for the image, generate several thumbnails, and insert them using a WYSIWYG editor using the default filename. For better or worse the new process is more manual. I have to move an image by hand and paste the filename into Markdown. So far I do prefer this new approach. Wordpress ends up puking thumbnail images everywhere, even in dimensions which are never used. During the migration I even discovered that for each image I've uploaded via Wordpress there would be both an image.jpg and a duplicate named image1.jpg!
And finally, I can no longer schedule a post to go live in the future, a Wordpress feature I'll miss dearly. As an example, I would often write up a three part series during the weekend and have them publish on Monday, Wednesday, and Friday morning. In theory I could rebuild this using a CRON job, but again, it might not be worth the effort.
Migration Process
At the beginning of the migration process the site had over 400 posts. The ideal post format is basically the same format used by Jekyll: a Markdown document with embedded YAML metadata (affectionately referred to as frontmatter). Thanks to the jekyll-exporter Wordpress plugin I was able to export posts in a mostly-working format. Many of the posts still contain HTML instead of pure Markdown, but they render just fine.
The exported YAML was a bit rough. I manually modified each file to adhere to a cohesive format. Since the site doesn't use Jekyll, certain features become superfluous such as id: 123, author: Thomas Hunter II, and layout: post. Fields like title: and date: remain vital. These changes were easily automated using the sed command. Other changes like merging categories with tags and consolidating their entries were a bit painstaking.
The old YYYY/MM image folder format is fine and is still used by the new site. Wordpress stores them in a directory called wp-uploads which was renamed to a more generic media. Those pesky thumbnails, however, just had to go. The following one-liner was all it took:
# Delete all Wordpress image thumbnails
find . -type f -regextype posix-egrep -regex ".*/.*-[0-9]+x[0-9]+\.(jpg|png|gif)$" -delete
Not all posts are worth keeping, even when considering the aforementioned deprecation feature. About 140 posts were deleted in the making of this website.
Parting Thoughts
I love this new system. It gives me enough control to be creative with features and UI. Building a layout from scratch—and not basing it on an existing template—really makes the site feel like it belongs to me. In the age of GitHub, Markdown has become second nature to software engineers—myself included—and this makes content writing an absolute pleasure.
Thomas has contributed to dozens of enterprise Node.js services and has worked for a company dedicated to securing Node.js. He has spoken at several conferences on Node.js and JavaScript and is an O'Reilly published author.
/r/node
Hacker Newsnews.ycombinator.com