On using Service Workers with Static Content
Support this website by purchasing prints of my photographs! Check them out here.Time and time again some cool new thing comes along and web developers are told to drop in some imperative JavaScript code to make our webpages faster or better. Invariably, time passes, and we realize that if we rip the new code out our webpage is simpler and faster and better without it. Are Service Workers just another fad?
Imperative Code: telling the computer how to do something—like a
forloop iterating DOM elements and setting their style to bold.
Declarative Code: telling the computer what you want—like using CSS to embolden elements matching a selector.
Service Workers are imperative JavaScript files. This code runs in a slightly different paradigm. It does so as a background worker with access to a subset of globals, limited network operations, and no DOM access. Unlike a Web Worker, there's no 1:1 association with a currently running webpage. It also brings with it a pretty hefty API.
I'm willing to bet that the world only needs, at most, a dozen unique Service Worker scripts for websites with static content (ignoring the declarative configuration within, such as lists of URLs). If such a list of defacto Service Worker scripts doesn't already exist I'm sure they will within a year.
What kind of differentiators for caching strategies are we talking about? Well, from a purely declarative point of view, imagine concepts like these:
- Load from network, unless offline, otherwise from cache
- Load from cache, unless missing, otherwise from network
- Upon visiting the site, cache a predefined list of assets
- Cache high DPI images if applicable, otherwise low res
- Expire assets after a certain amount of time
Such caching logic should be implemented by the browser and be enabled declaratively. The gritty details used to implement the cache should be provided by a deeper specification which the typical engineer doesn't need to scrutinize. However, with the caching mechanisms left to us engineers we're going to end up with a ton of (mostly wrong) implementations.
Mozilla created the serviceworke.rs site, which is a sort of cookbook approach for building custom Service Workers. The site is interesting, but I was surprised to find they didn't have an example for my use-case—always loading from network but reading from cache when offline. The site is useful for developing your own Service Worker, but the examples it provides aren't the finite list of defacto Service Workers I'm anticipating.
Obsolete: Application Cache
Service Workers were created to make up for the inadequacies of a previous technology: the now-deprecated Application Cache. Here's what an Application Cache file might look like:
CACHE MANIFEST
# v1 2011-08-14
# Example from MDN
index.html
cache.html
style.css
image1.png
# Use from network if available
NETWORK:
network.html
# Fallback content
FALLBACK:
. fallback.html
In the above example the cache file is declaring that the index.html, cache.html, style.css, and image1.png files should be cached for offline use once downloaded. The network.html file must always be accessed from the network. If no network connection is available then fallback.html should be used as a fallback for URLs beneath the current location.
This approach is entirely declarative: simple lines of text describe how the cache should work. There's no “code”. The cache file itself is referenced at the top of the HTML document, e.g. <html manifest="example.appcache">, where example.appcache is the name of the cache file.
The Application Cache came with a few footguns. For example, if the cache file is accessed and has been altered, this would signify that the site has been updated and the browser should rebuild the cache. However, if the filename for the cache was added to the cache file, the cache would cache the manifest and the user would never download newer updates. See Application Cache is a Doucebag for more footguns.
What new functionality do Service Workers provide?
Offline Viewing: Service Workers didn't bring us the ability to view a page while offline. The (admittedly buggy) Application Cache we looked at already did this. In theory the original Expires HTTP header does offer this, though in practice browsers throw away such cached entries all the time.
Offline Data Queue: Service Workers didn't bring us the ability to queue up operations while offline. Imagine a large SPA like Gmail allowing a user to write an email and click send while the browser is offline. A Service Worker could intercept the POST request and cache the email using IndexedDB. Then once the network connection was regained it could replay the POST requests, thereby sending the email.
However we already had the ability to cache data while offline using the navigator.onLine API. This provides a property which states the current online/offline status of the browser, and events which fire when going online and offline. Even before that feature existed we had the ability to make an AJAX request to determine if we're online. In these situations the SPA can determine if it's offline, if so queue the operations, if not replay them.
Mobile Web Apps: Service Workers didn't bring the ability to launch web apps directly from a mobile home screen. Both Android and iOS already allowed us to do so if various other criteria was met.

In the above screenshot Maps, Fit, and Spotify are all native apps. Radar Chat and The New York Times just have a meta tag for setting the viewport size (and a Web App Manifest JSON file for controlling the icon). Thomas Hunter II uses a Service Worker. Sure, the icon no longer has the Chrome emblem (and it also appears in the Android app launcher) but these are implementation details chosen by Android and don't indicate the abilities of Service Workers.
Data Pushes: Service Workers didn't bring the ability for a web server to push data to the browser. We already had that with WebSockets (not to mention HTTP long polling).
Offline Data Pushes: Service Workers did bring the ability to receive messages pushed to the client from the server by way of the Push API, which can run even when the page is not open.
My Approach
The philosophy I've taken with the Service Worker on this site is that content should be retrieved from the network whenever possible. Each time an asset is retrieved it should then be put into the cache. Only when a network request fails, i.e. the user is offline, should we ever check the cache for the asset. I chose this approach because my website is already quite fast, I simply want users to be able to view content when offline.
Install and Activate
Service workers work by registering global events which fire at various stages in their lifetime. The first two events, called install and activate, do initialization work and are what we're going to look at first.
/**
* Unlike most Service Workers, this one always attempts to download assets
* from the network. Only when network access fails do we fallback to using
* the cache. When a request succeeds we always update the cache with the new
* version. If a request fails and the result isn't in the cache then we
* display an Offline page.
*/
const CACHE = 'content-v1'; // name of the current cache
const OFFLINE = '/offline'; // URL to offline HTML document
const AUTO_CACHE = [ // URLs of assets to immediately cache
OFFLINE,
'/',
'/service-worker.js',
'/manifest.json',
'/styles/main.css',
'/scripts/main.js',
'/scripts/highlight.js',
'/favicon.ico',
'/images/icon-152.png',
'/avatar.jpg',
'/scripts/countly.min.js',
];
// Iterate AUTO_CACHE and add cache each entry
self.addEventListener('install', event => {
event.waitUntil(
caches.open(CACHE)
.then(cache => cache.addAll(AUTO_CACHE))
.then(self.skipWaiting())
);
});
// Destroy inapplicable caches
self.addEventListener('activate', event => {
event.waitUntil(
caches.keys().then(cacheNames => {
return cacheNames.filter(cacheName => CACHE !== cacheName);
}).then(unusedCaches => {
console.log('DESTROYING CACHE', unusedCaches.join(','));
return Promise.all(unusedCaches.map(unusedCache => {
return caches.delete(unusedCache);
}));
}).then(() => self.clients.claim())
);
});
One of the shortcomings of the Application Cache is that it was possible to write a cache in such a way that it would cache assets forever. In order to combat this situation, Service Workers were written so that any time the actual Service Worker JavaScript file is changed it would then run the activate event again. This should prevent situations where certain data can never be removed from the cache.
This is also why the above file has a CACHE variable. Each time I modify and published the script I also increment this variable. The browser then iterates through any caches not matching the new cache name and destroys them.
The CACHE, OFFLINE, and AUTO_CACHE constants in this file are configuration, unique to each site, whereas the remaining code is general purpose and potentially usable by others.
Fetch
The third event, fetch, is where things get interesting. This is where we actually intercept a network request and implement our caching logic.
self.addEventListener('fetch', event => {
if (!event.request.url.startsWith(self.location.origin) || event.request.method !== 'GET') {
// External request, or POST, ignore
return void event.respondWith(fetch(event.request));
}
event.respondWith(
// Always try to download from server first
fetch(event.request).then(response => {
// When a download is successful cache the result
caches.open(CACHE).then(cache => {
cache.put(event.request, response)
});
// And of course display it
return response.clone();
}).catch((_err) => {
// A failure probably means network access issues
// See if we have a cached version
return caches.match(event.request).then(cachedResponse => {
if (cachedResponse) {
// We did have a cached version, display it
return cachedResponse;
}
// We did not have a cached version, display offline page
return caches.open(CACHE).then((cache) => {
const offlineRequest = new Request(OFFLINE);
return cache.match(offlineRequest);
});
});
})
);
});
This part of the script has a lot more going on. First, if a request to a third-party file or a non GET request is made then we just fall through to the fetch function, essentially ignoring the Service Worker. Otherwise we make the request, insert the response into the cache, and reply with the response. If the request fails, i.e. we're offline, then we check to see if we have the asset cached. If so, reply with the cached version. Otherwise, reply with a cached version of the /offline page.
At first glance this approach appears as though every time an asset is needed it will result in a network request. However, Service Workers still make use of the browser cache. Think of them as being a new layer between application code and the existing browser cache. The fetch calls will resolve cached assets before hitting the network.
Application Code > Service Worker > Browser Cache > Network
Debugging Service Workers (in Firefox) is Difficult
Debugging a faulty Service Worker can be quite difficult, especially if you're in my situation where such errors only affect Firefox. If your fetch() call fails you'll get a stack trace, though you won't necessarily know what caused the error. No matter what the underlying network error the message in the console resembles the following:
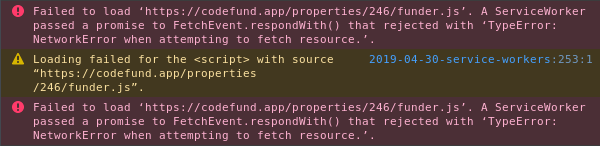
What's causing the failure in the above situation? Well, recall that the Service Worker isn't associated with a running webpage. This means the true network requests are hidden from the network tab in Firefox's DevTools; we get access to the pseudo network requests between the page and the Service Worker.
When a Service Worker returns an invalid response there won't be an associated stack trace. This means you may encounter cryptic errors such as this one:
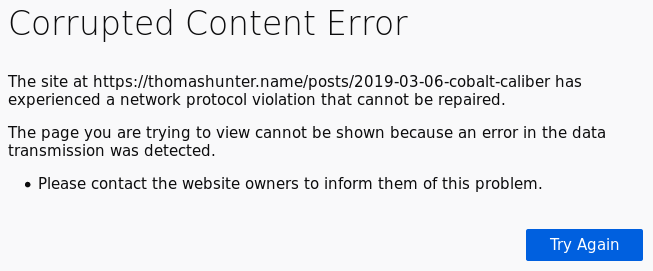
My personal favorite is when a faulty Service Worker returns the offline fallback page even when the connection is perfectly fine. I've encountered many pages like this over the past few years which, ironically, was my first introduction to Service Workers:
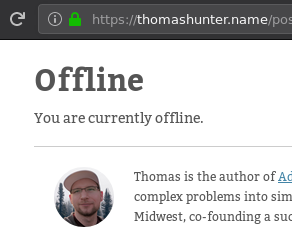
Google Chrome has a much better approach. When the DevTools are open, all network requests made by a Service Worker associated with the current page will be displayed. Recall that there is not a 1:1 mapping between currently loaded page and Service Worker. That means any requests made by the Service Worker but not for the current page (i.e. another tab is open) will still be displayed.
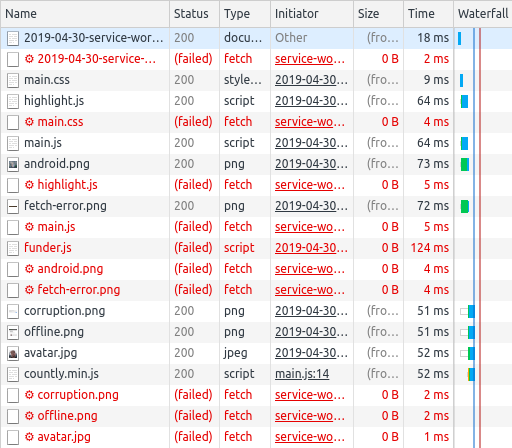
This also means it's not possible to automatically associate a Service Worker request with the corresponding Network request (which would be useful for contextually extracting error information). But, usually as a human we're able to associate the requests together. For instance, it's pretty obvious that the main.js request being sent to my Service Worker is associated with the main.js request which was sent to my server. I can then click on the real network request to find out if it's a 404 or CORS error.
Conclusion
Service Workers feel like an attempt to solve too many problems at once. They provide redundant methods for implementing existing browser features. Their primary use is to provide a developer with a high amount of control over caching static assets. But, they provide too much control. Much like the Application Cache they replace, they come with their own unique set of footguns. They're difficult to debug. They're hard to reason about (what's the one-sentence elevator pitch?)
Personally I would have liked to have seen an Application Cache 2.0… Some sort of declarative approach which made up for the shortcomings of its predecessor. For example, could many of the issues be solved by including a preamble section with key/value configuration pairs? Could we have configuration settings adjacent to URL entries? It's hand-wavey, but maybe something like this:
CACHE MANIFEST
# v2 2018-04-30
PREAMBLE:
ignore_cache_if_online: true
ignore_third_party_redirects: true
ignore_manifest_cache_header: true
bypass_cache_for_network_requests: true
CACHE:
index.html
cache.html
style.css
image1.png @dpi:<300
image1@2x.png @dpi:>=300,<500
image1@4x.png @dpi:>=500
NETWORK:
network.html
FALLBACK:
. fallback.html
I'm only now writing about Service Workers, but I've had them installed on this site for two months by now. Unfortunately, with the headaches they bring, and with the uncertainty that my visitors are actually reading my content and not viewing the offline page, I'll probably be removing them very soon.
Thomas has contributed to dozens of enterprise Node.js services and has worked for a company dedicated to securing Node.js. He has spoken at several conferences on Node.js and JavaScript and is an O'Reilly published author.